

#machine-learning #data #data science
13. Jan. 2020 |
- min Lesezeit
Wie bringt man ein erfolgreiches, datengetriebenes Produkt auf den Markt? Einer der grundlegenden Schritte ist es sich mit den verfügbaren und benötigten Daten auseinander zu setzen. Bei der Unmenge an Daten heutzutage kann dies leider sehr schnell zu Verwirrung führen. Abhilfe schafft hier: der Data Landscape Canvas. Er verschafft schnell einen Überblick, zeigt Schwächen und Lücken der vorhandenen Daten auf, um im Chaos des Daten-Dschungels nicht die Übersicht zu verlieren.
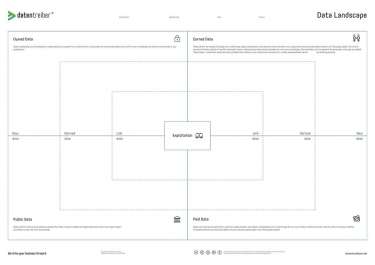
Ähnlich wie der Business Model Canvas, ist der Data Landscape Canvas eine Methode um komplexe Informationen in einer kompakten Art und Weise auf Papier zu bringen. Er eignet sich für die Zusammenarbeit und hilft Dinge visuell und nachvollziehbar für andere darzustellen. Darüber hinaus konzentriert er sich dabei auf Datenquellen, ihre Verbindungen und wie man sie verwertet.
Die folgenden 4 Felder bilden dabei das Grundgerüst:
Wobei der Landscape Canvas für jedes der Felder zwischen den folgenden 3 Kategorien unterscheidet:

Idealerweise befüllt man den Data Landscape Canvas im Workshop Format mit einem interdisziplinären Team. Man entscheidet sich zunächst für einen Use Case und platziert ihn in der Mitte. Der weitere Prozess lässt sich grob in vier Schritte unterteilen:
Dabei ist zu beachten, dass man sich von außen nach innen vorarbeitet unter Beachtung der Reihenfolge. Man fängt also mit den “Owned” Rohdaten an, leitet daraus abgeleitete “Owned” Daten ab und erstellt zu guter Letzt “Owned” Verknüpfungsdaten. Dies wiederholt man für die anderen Felder bis man bei “Paid”-Daten angekommen ist. Logischerweise ist es vorteilhafter, wenn möglichst eigene Daten bezahlten Daten vorzuziehen - daher auch die Reihenfolge. Hat man den gesamten Data Landscape ausgefüllt, kann man nun einen Abgleich mit den Anforderungen an das Produkt durchführen und somit mögliche Datenlücken identifizieren.

Der Data Landscape Canvas schafft eine solide Ausgangssituation, auf deren Basis man eine effektive Datenstrategie definieren kann.
#machine-learning #data #data science

#data #data science #data thinking

#data #databased #datascience

#digital log #podcast #vodcast

#head of data #data science #team

#datascience #internship #maths

#trends #healthcare #data science

#data #dashboard #data-driven-product

#datascience #datathinking #aideate
